
TLDR;
Я переключился с PHP на Kotlin и надеялся, что в мире Java все по полочкам, уж точно не хуже, чем в PHP, где спустя 4 года путаю где needle с haystack в параметрах функции. У меня появился шанс. Это был софт, где основным хранилищем данных была Kafka. Идея использовать Kafka, взята из книги Designing Event-Driven Systems: Concepts and Patterns for Streaming Services with Apache Kafka (Ben Stopford). Идея в том, что система хранит набор событий, по которым текущее состояние можно восстановить. Это дает как преимущества, так и недостатки.
Дано
Начало проекта. Нет команды, нет стэка, не выбран даже язык разработки. Не хватало только гаража. Есть опытный, скиловый технический директор из Портлэнда и желание стартовать проект. Средний руки php-разработчик (это я) в поисках проекта. Первый созвон, знакомство, описание проекта в общих чертах, концепция, событийный подход, набросок архитектуры, ссылка на книгу Стэпфорда и желание услышать обратную связь. Я недолго думая согласился, мне было интересно начать с нуля, да и в самой идее было что-то любопытное.
О событийном подходе
Есть пациент, ему назначают план лечения. План лечения это приём лекарств, процедур и т.д. Стандартный подход это внести изменение на клиенте, передать на backend, внести изменения в базу, вернуть результат. В каждый момент времени доступно определённое состояние данных. Можно пойти другим путём: собирать изменения и тогда последнее изменение будет определять текущее состояния. При этом состояние может быть восстановлено из прошлых событий. События можно использовать не только для восстановления состояния, но и для логирования, аудита, отладки и контроля. Теперь можно легко ответить на вопрос "Почему система пришла в такое состояние?". Это и есть суть событийного подхода.

Рисунок 1. Сохранённые события упорядоченные в хронологическом порядке.

Рисунок 2. Описывает состояние данных.

Рисунок 3. Описывает эволюцию.
Начало проекта
Определяли язык, стэк технологий, стиль, подход к разработке. Было много обсуждений. Почему Kotlin, почему не Python, почему не Java. Может не Kafka, может есть альтернативы, kotlinовский фреймворк или Spring, Graphql или Rest и т. д. Kotlin был выбран из-за того, что это свежий язык, с синтаксическим сахаром, у которого под капотом Java, он совместим с Java и в любой момент мы можем переключится на нее и даже нанимать Java разработчиков. Ничего не теряем. От чисто kotlinовского фреймворка мы отказались, чтобы не пилить велосипеды. Не хотелось отвлекаться на написание библиотек, а шансов найти готовую, даже в нескольких экземплярах на Spring гораздо больше. Graphql выбрали за возможность писать, валидировать схему, наличие поддержки в том же Spring и чисто поржать (шутка). Проект стартовал с задач вроде "ознакомится со стэком, kotlin + ORM, нужна ли hibernate, сделать шаблон для сервиса, сформулировать вопросы, проблемы, что не ясно и т.д.". Позже мы часто общались по событийному подходу.
Въезжаем в проект
Пока въезжал в идеи, читал книгу и развлекался с Kotlin, я писал сервис для хранения данных пациентов. Его выделили в отдельный сервис. Это был приватный REST-сервис с данными пациентов. Событийный подход решили не использовать по нескольким причинам. Во-первых нельзя допускать утечек и "размазывания" данных по системе, удобно хранить данные в одном месте, легко выполнить требование об удалении данных по запросу. Это был первый сервис, написанный мною на Kotlin + Spring Boot.
Другая история была связана с интеграцией Kotlin и Hibernate. CTO вторую неделю дружил Kotlin и Hibernate. Оказалось, что там много подводных камней. Тогда приходилось собирать эту информацию по крупицам.
Дальше было про взаимодействие с frontend. Выбрали GraphQL. Схема была примерно такая: делаем API схему мутаций и запросов, согласуем с frontами, делаем backend и frontend параллельно, выкатываем backend на dev, добиваем frontend, тестим, устраняем баги, deploy. В целом Graphql показался удобной штукой. Единственное, что я припоминаю из странностей, так это ограничение на входной и выходной тип.
Событийный подход, на первый взгляд, хорошо ложится на Kafka. Kafka это быстрый, надёжный commit log. Гарантирует порядок сообщений в рамках партиции, есть возможность читать из определённой партиции по ключу, указав временную (либо числовую - смещение) метку, начиная с которой хочешь получить события. Остановлюсь подробнее на событиях. Во-первых они являются "источником истины". Во-вторых важна хронология. В-третьих события неизменяемы и хранятся в системе продолжительное время.
Общая схема, первые сервисы, первые испытания
Спустя какое-то время мы выкатили наработки в dev-окружение и работало это следующим образом:
-
Сервис получает запрос от frontend приложения и если это mutation, то создаёт событие (команда) и отправляет в Kafka.
-
Если запрос на данные (query), то берет из локальной базы и возвращает.
-
События из Kafka читают другие сервисы, обрабатывают и пораждают свои события, которые снова летят в Kafka.
-
Каждый сервис имеет своё локальное хранилище, в котором хранит всю необходимую для сервиса информацию.
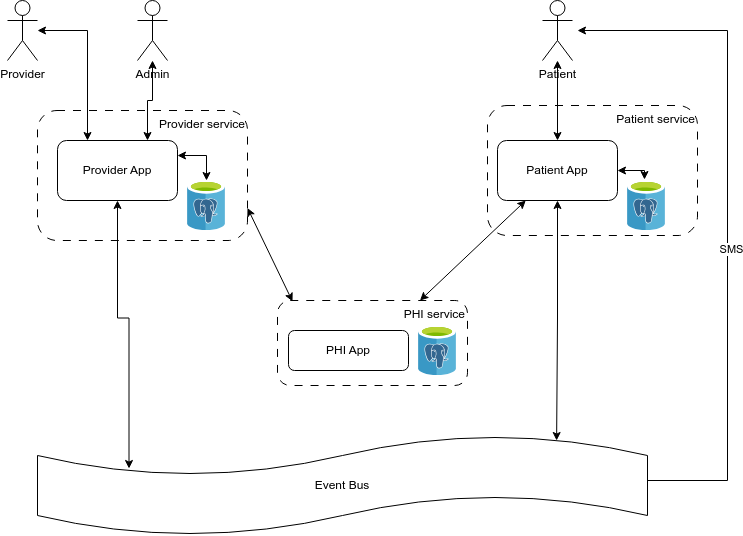
Рисунок 4. Сервисы
Собственно это все, что я хотел рассказать и теперь пришло время подвести итоги и поделиться своим мнением. Отмечу моменты, которые мне показались важными:
-
Сложность на старте. Разработчики не привыкли к такому подходу и даже инженерам с опытом требуется въехать и понять на кой черт оно вообще надо. Это гораздо сложнее, чем crud приложение.
-
События на каждый чих. Любое изменение должно быть в Kafka. Событий возникает много. Есть события простые, вроде обновления поля, есть бизнесовые. Обработку простых событий можно автоматизировать, более сложные придётся писать руками.
-
События навсегда. Иногда нужно изменить событие, добавить поле, убрать поле и т.д. Следует иметь в виду всю прошлую историю и иметь возможность вычитать и обработать все события при необходимости.
-
Дублирование. Я говорю про дублирование моделей и кода. Часто возникала ситуация, когда практически одни и те же сущности были созданы и для Patient и для Provider приложений. Предполагается, что сервисы независимы и за них отвечают разные команды и вроде бы это норм, но глаз режет.
Пожалуй, никогда не скажу, что такой подход является универсальным. Однако у него есть преимущества и фишки, которые я тоже отмечу:
-
Поскольку данные лежат в Kafka, то новый сервис может вычитать данные с самого начала, за прошлый год или же начать с самых свежих данных постепенно обрабатывая старые. Здесь есть некоторая свобода и независимость.
-
Аудит. Получая данные из кафка и фильтруя их по id можно наблюдать как менялось глобальное состояние системы для конктретного пользователя.
-
Отказоустойчивость. Сервисы могут быть независимы друг от друга. К примеру выход из строя Provider Service никак не влияет на Patient. Тут есть где подискутировать, но в общем и целом можно построить систему, чтобы одна группа пользователей обрабатывалась определёнными сервисами при этом выход из строя других сервисов никак не влиял на систему глобально.
-
Аудит из коробки можно использовать для отладки и решения проблем и для ответа на вопрос "как возникла эта ситуация?"
Дальше я бы хотел поговорить про трудности, с которыми мы столкнулись.
Согласованность в конечном итоге (eventually consistent). Асинхронность даёт независимость и отказоусточивость, но порождает ситуацию, когда не все части системы синхронизированы. В конечном итоге система синхронизируется, но для этого нужно время. Подобные задержки приводят к тому, что пользовательское приложение должно отображать актуальные данные и учитывать асинхронную модель поведения.
Продумать заранее. После записи события в лог его будет сложнее исправить или удалить. Нужно заранее продумывать как хранить данные в топиках, устанавливать корректное время хранения, думать про компактификацию. Если событие попало в историю и потребитель не может его обработать, то нужен механизм, который решит эту проблему.
Kafka это не игрушка. Всегда найдутся те, кто скажут, что просто нужно уметь готовить. Никто из команды готовить Kafka не умел. Сейчас, конечно я знаю больше, чем тогда, но я бы шел в проект с Kafka, там где есть человек, который будет сопровождать и понимает как она работает. Kafka рассчитана на огромный поток событий и у нее бешеная производительность и это не просто очередь сообщений, я бы сказал, что это вообще не очередь сообщений. Я насчитал больше сотни параметров, отмеченных как high importance при конфигурации Kafka и вся "прелесть" в том, что они не независимы. Есть большая вероятность того, что из Kafka не подойдёт вам из коробки и преподнесёт сюрпризы вроде ребалансировки партиций, компактификации, retention policy и случайно одинаковых group.id у консьюмеров при запуске нового сервиса или череды таймаутов.
Hibernate всячески пытался играть со мной в напёрстки. Все время. Все эти состояния, Persistence Context, LazyInitializationException, 10 запросов вместо ожидаемого одного, разноуровневые кэши, equals и hashcode, HQL/JQL, Criteria, open-in-view = true. Меня не один раз посещала мысль написать сырой запрос в базу данных и промапить на объект ручками. Надо списать на то, что я пользовался hibernate впервые и, возможно, нужно как-то сжиться с ним, но порой очень сложно понять, что происходит под капотом.
В общем и целом сложно назвать Event-driven подход универсальным. Если обкатать подход и набить шишки, постичь сложность Kafka (или альтернативы) и hibernate, то может получиться надёжная асинхронно работающая система, хранящая события за длительный период времени с возможность восстановления состояния.
Ссылки
Прошлые записи
- Решение простой задачи как способ познакомиться с языком программирования Go
- DYI. Гипсовый карниз своими руками
- Комната призвания
- Разбираемся с Coroutine в Kotlin - часть четвертая
- Разбираемся с Coroutine в Kotlin - часть третья
- Разбираемся с Coroutine в Kotlin - часть вторая
- Разбираемся с Coroutine в Kotlin - часть первая
- Отпуск длинною в год
- Подходит ли data class для JPA Entity?
- Код 2015 против 2023